Introduction to Website indexing
All web spiders follow the same basic concept during indexing - they start at a given web page, the so called Starting URL(s), and 'explore' onwards from there, following links and retrieving pages in a systematic way until either the entire site has been visited, or until some configured limit has been reached.
Spidering is an inherently slow process. Spidering the entire Internet could take months or even years, and spidering an individual site may take hours or days. Spiders need to visit every page, even if only to determine that nothing has been added or changed.
Direct disk access methods such as network mapped drives, NFS or FTP are much more efficient than spidering since the indexing engine can obtain a 'directory' of information in a structured way, and only retrieve those portions that are necessary.
Spidering is the best option in situations where a mapped drive or FTP link is not available, for example:
- The information resides in a non-file format, such as Lotus Domino.
- The information resides on a 'foreign' server for which you will not be given NFS or FTP access, such as a third party site or even a competitor's site.
- The information resides within your own company, but you choose not to make NFS, FTP or drive mapped access available for security or system management reasons.
The beauty of a spidering approach is that any information which can be accessed via a standard browser can also be included in your index. Therefore one search method can provide integrated, homogenous search and retrieval.
The only downside of spidering is the time required to perform the actual traversal of the nominated site or sites. Obviously this will depend on the size of the site and the speed of the link between yourself and the site. However, spidering is a 'batch' operation, and Perceptive Search provides many options to control frequency of traversal, etc. Moreover, your index is fully functional while spidering progresses.
Once a full traversal has been completed, you will want to keep your index up to date. The way to do this is repeat the traversal at regular intervals. Even though a full traversal may take many days on large slow sites, updated information can be posted to the index at regular intervals as it becomes available.
With WebSite spider, you can have as many sites as you like traversed with whatever mixture of frequencies you want.
WebSite Spider is also highly configurable with respect to index updating granularity, MIME Types, file name patterns, multiple threads, and security.
Please note additionally that WebSite Spider provides a variety of options to adjust which pages are crawled through and which pages and documents are included in the index to enable searching them.
For example if you have access the HTML source of a website you can control the content the spider indexes within a HTML file. The spider will index content from the top of the page until the first <!-- ISYSINDEXINGOFF --> HTML comment, and only start again if it finds a <!-- ISYSINDEXINGON --> comment. It can be switched off and on as many times as needed, and doesn't affect the pages display. In this way sections of the page can be excluded from indexing, and therefore will never be found as a hit in that page. Prime candidates are headers, footers, navigation panels, adverts, etc., which appear on every page.
Understanding Levels
In an ideal world, every site would be a simple hierarchy, as shown below:
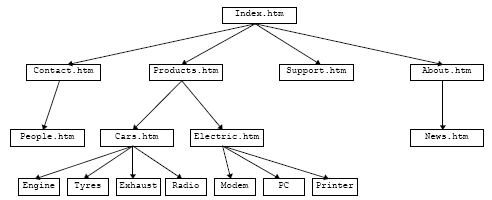
However, life in general, and web sites in particular, do not follow simple hierarchies. Pages point across at other pages, and point back up the tree in a structure sometimes known as a Plex.
This is not a bad thing, and reflects the way peoples minds work. For example, the News section might have a link to a new product; a product might link over to whom to contact about that product. A product may belong to more than one category, and even the front page might link directly to a page further down the 'hierarchy'. A more realistic example might look as follows:
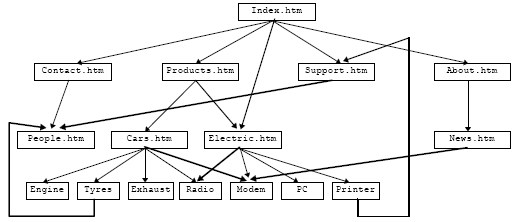
This is why they call it the World Wide Web, and not the World Wide Hierarchy.
The difficulty this creates is in deciding what depth level a particular page is at. For example, is the 'Printer' page at level three or level two? Is the 'Tyres' page at level three or level seven (via products, electric, printer, support and people)? The answer of course, is that the level of a page depends on the path you took to get to it. In any reasonably sized web site, there are many paths to each page, and the level of a page is probably best described as the shortest of all the possible paths that leads to that page.
As the Spider navigates, it has no way of knowing whether it will encounter a shorter path to the same page sometime in the future.
For example, let's say you've asked it to spider the first five levels of a site. It may visit a particular page that has many links to elsewhere, but decide not to follow those links because the current page was already five levels deep.
Later in the traversal, it might find a shorter path to the same page, and the page is now considered to be at level four. The Spider needs to re-retrieve that page, and re-process the links, this time following them because they are now within the five level scope.
Even later in the traversal, it might find an even shorter path to the same page, and might now consider it to be at level two. Obviously the page needs to be revisited, the links followed, and the pages pointed to need to be reprocessed as well, since their links (although not processed before) now fall within the scope and should be processed.
Moreover, in the process of doing this, the Spider may discover another short-cut to another page which had been previously visited, and that page may change from a leaf (level five) page, to something of a numerically lower level and need to be revisited.
You can see from this example the process of 're-leveling', or the discovery of short-cuts and the need to revisit, can be quite time consuming, and may be responsible for a large percentage of page visits.
For this reason, if your intention is to spider the entire site, it is better to set the Crawling Depth for the appropriate Starting URL to "Unlimited", rather than just specify a very large limit. When Perceptive Search knows all levels are to be spidered, it can dispense with the whole re-leveling process. However this process might be very time and bandwidth consuming, so should be chosen with care.
Another option to reduce re-leveling might be selecting the Breadth First Navigation Strategy on the Navigation Pane. Depending on the site structure this option may result in less re-leveling.
If you know a site has a certain number of pages, and WebSite Spider is reporting to have visited more than that number, then re-leveling is almost certainly at play. Either select the 'No Limit' option, or change the navigation strategy.