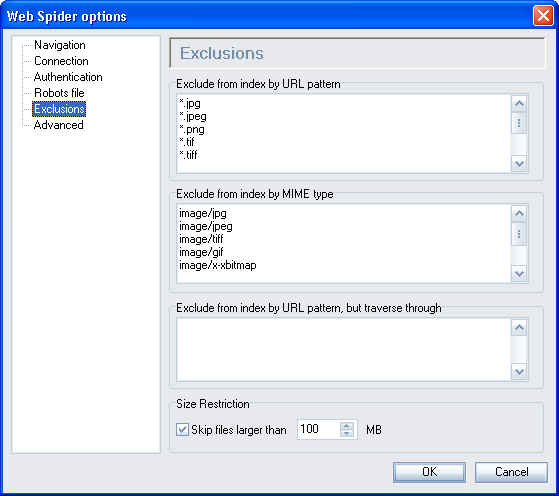
Exclusions
 View thumbnailView full size image
View thumbnailView full size imageThe Accepted and Ignored patterns control the files (pages) retrieved, and are much more efficient than screening based on MIME types because Perceptive Search does not need to retrieve the file for this check.
Exclude from index by URL pattern
Lists the URL patterns to be ignored, and therefore neither parsed for links nor processed into the index. This patterns match against the whole URL, i.e. they do match against parameters after the file part. For example, the page with the url 'MyPage.jsp?action=print' is not matched by the pattern '*.jsp', but by the pattern '*.jsp*'.
You can combine wildcards in both the Accepted File Patterns and Ignored URL Patterns lists. Where a file name matches a pattern in both lists, the most specific pattern it matches (that is, longest) is the one that applies. Note that the comparison is done using the full path and file name of the URL, and compared against the wildcard pattern given. The pattern can include any number of '*' and '?' symbols. For example, to match MyPage.Htm in the root, use the pattern '/MyPage.Htm'. To match it at any level, use *MyPage.Htm'. To match all files in the 'MyDir' directory, use '*/Mydir/*'. The pattern matching is not case sensitive.
Exclude from index by MIME type
Determines which MIME types will not be processed by the Perceptive Search index. MIME types can be thought of as file types. When a web server sends a file (such as a page), it sends a header to specify its MIME type, so that the browser knows how to handle the file.
By default, Perceptive Search accepts the most common MIME Types (such as HTML and plain text). You can change the MIME types that Perceptive Search will process by adding or removing them from this list.
Exclude from index by URL pattern, but traverse through
Allows you to exclude certain URLs from being indexed, however, the links contained on these pages are still traversed and indexed. Enter a pattern that will match the URLs you wish to exclude from the index. For example, to exclude all files under "/sitemap/", enter */sitemap/*.
Size Restrictions
You can configure Web Spider to skip pages or files larger than a certain size, using this option. Sometimes, large files may be dumps, logs, archives, or other types of files that are not worthy of indexing.