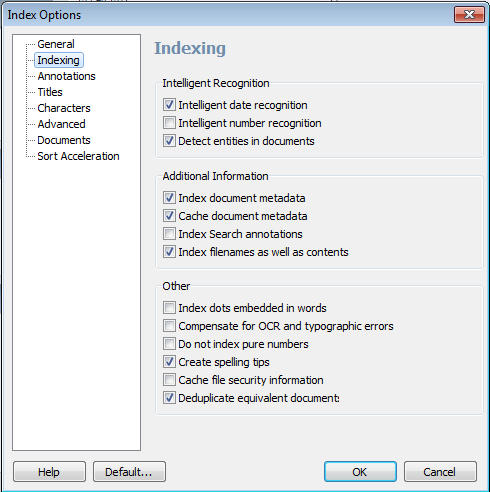
Indexing options
Change specific options relating to how the current index works with documents. The recommended options are shown selected.
 View thumbnailView full size image
View thumbnailView full size imageIntelligent Recognition
Intelligent date recognition
By selecting this option, Perceptive Search will be able to recognize a variety of date formats in queries and documents. Examples of valid dates are:
- 4 15 94 or 4-15-94 or 4/15/94
- April 15th, 1994 or 15-apr-94
- 15 4 94 or 15-4-95 or 15/4/94
- 940415
- 15th day of April, 1994
Dates are located regardless of the form in which they are expressed in the query or in the document. For the purposes of proximity searching, the date is considered to be a single hit, even if the date is actually expressed in three or four words. The exact location of the hit is taken to be that of the last component of the date. This is why only the final portion of the date sequence is highlighted in the Perceptive Search Browse window.
Note: Selecting this option will slightly increase the size of your indexes. Unless your data is mostly dates, the increase in index size should not be significant. Enabling the feature may also slightly reduce indexing performance.
If you intend to use the Intelligent Date Handling option on highly numeric data files, such as financial transactions that contain primarily numeric data intermixed with dates, and if you expect the dates to be in YY-MM-DD format or MM/DD/YY format, it is recommended that you configure your Perceptive Search index with the "-"or "/" character defined as either significant or insignificant (see Character Options). That is, do not take the default of "-" being interpreted as a word delimiter (punctuation character). This will greatly assist Perceptive Search in making the correct interpretation of the dates when they appear in highly numeric data.
Where a date is ambiguous, for example 1-4-94, Perceptive Search resolves the day/month ambiguity according to the regional settings that were in effect when you started Perceptive Search (i.e. the Regional options under Windows Control Panel).
Note: any ambiguity in the indexed data is resolved at the time the data is indexed, whereas ambiguities in a query are resolved at the time of the query. This means that you can index your source data with ambiguities resolved according to your REGIONAL settings, then ship the index to another user running a different REGIONAL setting. Perceptive Search automatically normalizes and remaps the ambiguities accordingly.
Intelligent number recognition
This option works in similar way to the Intelligent Date recognition option but for numbers only. For example, the number 1,029 could be expressed in any of the following ways:
1029
1,029
one thousand and twenty nine
one thousand, twenty nine
1,029.00
1 029
one zero two nine
a thousand and twenty nine
Perceptive Search will interpret each of the above examples as the same number.
The Index dots when embedded in words or numbers option will be automatically enabled
when Intelligent Number recognition is used.
Detect Entities in Documents
When this option is selected, Perceptive Search will identify the "who, what and where" entities involved in documents. The entities Perceptive Search recognizes include:
- People
- Organizations
- Locations
- Email addresses
- Website domain names
It does this automatically using a combination of heuristical and dictionary based techniques.
When queries are performed, Perceptive Search will find all the documents that match your search terms. As well as displaying the found documents, it will also provide an outline of the main entities involved in the cluster of found documents. This can be used to identify the key players related to your search term.
You can then drill-down by clicking on one of the entities, or the presence of an entity may even suggest a whole new line of enquiry. Sometimes the entity itself will constitute the answer for which you are looking (for example, what company does John Smith work for).
Perceptive Search Entity detection works very well without any sort of user configuration. But because it is being done by a computer rather than a person, it will occasionally mis-categorize entities. For example, "John Street". In general, Perceptive Search tries to avoid making judgements which should require human knowledge to make properly.
Other times, Perceptive Search may fail to recognize entities about which you care greatly. For example, you may be involved with organizations whose names are not being reliably detected by Perceptive Search, or dealing with individuals with unusual names. In these scenarios, you can augment the standard Perceptive Search lexicon to include your own local knowledge.
Index Additional Information
Index document meta data
Choosing this option will allow Perceptive Search to index the summary information in formats that support it, such as Microsoft Word, Excel, WordPerfect, Acrobat PDF and HTML. This information can then be searched on and will appear at the top of each document when browsed. This information can also be used in Field Level Searching: see Named Sections for details.
Cache document meta data
Store a copy of the meta data information in the Perceptive Search index for faster retrieval and processing. Allows for meta data to be used for document categories. Recommend if Index document meta data is enabled.
Index search Annotations
If selected, the indexer will automatically detect and index any text note annotations that have been created for documents in the index.
Because this option affects which files will and will not be indexed (much like an indexing rule), rather than affecting how previously indexed documents should be read (like Intelligent Date Handling or Smart Dot Handling), you can change it without Reindexing the index. Changes will just be reflected in the next Update run, just like a rule change.
Note: only the text annotations are indexed - not hyperactivities, images or linked queries.
Index filenames as well as contents
If you choose, to index filenames, you can search for files by their names, extensions or any portion thereof. For example:
TEST.DOC
TEST
TE*
MYDIR \\ ASC
Each portion of the filename is indexed as though it were a word located at the beginning of the document.
Other
Index embedded dots in words
When checked, dots occurring in the middle of a string of characters which appear to be forming a paragraph number are not treated as word separators. Dots are considered significant in cases like "3.2.12" but not significant at the end or start of a word, or embedded in longer strings such as "fred.smith". The feature is specifically for treating paragraph numbers as searchable entities.
Compensate for OCR and typographic errors
Also known as Fuzzy Precompensation.
The use of Fuzzy Precompensation is appropriate when you know your source data is likely to have a high proportion of errors as a result of being captured by means of Optical Character Recognition (OCR) scanning.
When Fuzzy precompensation is chosen, Perceptive Search queries will automatically and transparently retrieve words that it considers may be OCR scanning errors or other typographical errors. For example, searches for "duck" will also retrieve "cluck", as it is possible that the "d" was slightly broken and misread as a "cl" by the OCR process.
Perceptive Search uses sophisticated heuristical, algorithmic and statistical means to determine which words are likely errors of other words. In some cases, Perceptive Search may incorrectly suggest that one word is a misspelling of another. There will always be some degree of 'false alarms'.
It is recommended you inform your users when an index has been configured with the fuzzy precompensation feature enabled. This should avoid any possible confusion as to why additional words are being returned during their query activities.
Note: use of this feature will slightly increase your index size and indexing time.
Do not index pure numbers
This option treats pure numbers or words which are made exclusively of numerals (e.g. 765390) as common words. This means these numbers or words will not be indexed, and thus not be searchable. Note that this option has no effect on alphanumeric strings, e.g. A1234B, which are always indexed.
Note: changing this option will require you to perform a Reindex.
Create spelling tips
Creates a list of similar words for the Perceptive Search index, allows for 'Did you mean?' prompts for queries.
Cache file security information
Cache the NTFS file security descriptor at indexing time. This dramatically increases the speed at which result lists can be filtered to show only documents that are accessible to the current user (see Check document security before adding to result list).
The cached security information will be updated when documents are updated in the index, to force an update of the cache use the Actions -> Refresh Security. This can also be updated via a Scheduled Update task.
Note: some files may be shown in the result list that the user no longer has access to, though the document will not be able to be viewed.
De-duplicate documents in index
Setting this option will cause Perceptive Search to store a checksum of the textural content of each document. This can then be used at query time to de-duplicate the result list.
Note: de-duplicatation is based on exact duplicate, and will not de-duplicate on similar documents.